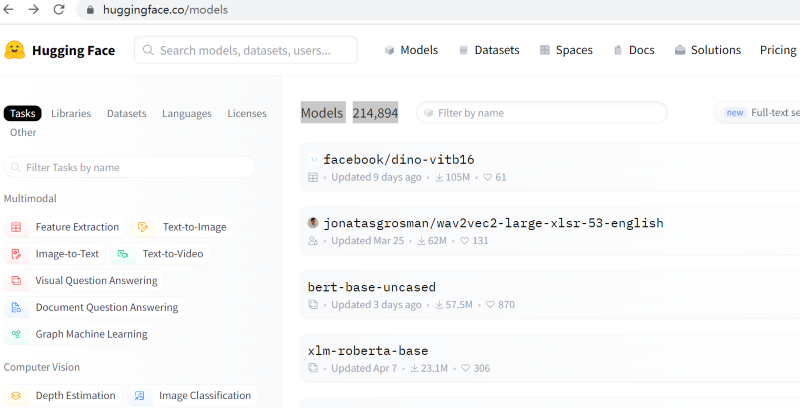
| Hugging face 刚开始准备聊天机器人,就在github上开源了一个Transformers库。 有心栽花花不发,无心插柳柳成荫。聊天机器人业务搞不起来,但是他们开源的Transformers库在整个社区迅速大火起来。然后就转行做开源模型库、数据集等,摇身变成了机器学习界的github。 地址是:https://huggingface.co/ 应该是不可多得的搞人工智能的网站,Github估计快哭了。 前达到: 模型数目: Models达到214,894个,哇,真是让人吃惊。包括Facebook,MS等都在上面开源了相关模型。
预训练模型是一个通过大量数据上进行训练并被保存下来的网络,从而节省从头训练的时间。可以将其通俗的理解为前人为了解决类似问题所创造出来的一个模型,有了前人的模型,当我们遇到新的问题时,便不再需要从零开始训练新模型,而可以直接用这个模型入手,进行简单的学习便可解决该新问题。就相当于我们相做吃饭,已经有人把米准备好了,而不需要我们去种拉稻子。大部分时间已经被预训练模型搞好了。 数据集数目: Datasets达到37,979个。
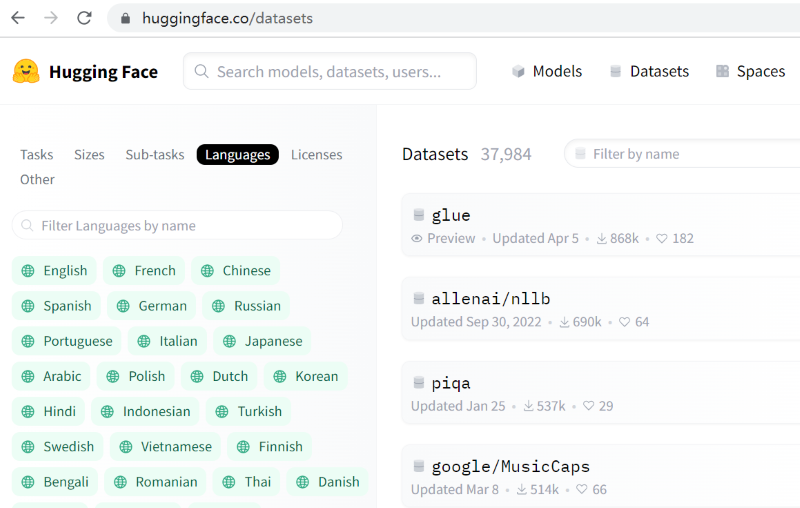
因为模型没有语言分类一说,数据集有。我们看下数据集分类后的结果:
点击Dataset, 再点击Languages,然后分别点击English, Chinese之类的 English: 3565个 Frech:387个 Chinese:356个 Spanish:353个 German:325个 Russian:310个 Portuguese:229个 Italian:210个 Japanese:198个 Arabic:193个 Polish:173个 Dutch:172个 Korean:162个 害,这跟我们大国地位好像不相称啊,开源数据集居然这么少,晕倒了。我们居然不是韩国、日本的十倍。 提高对人类文明的贡献,我们做得还是任重道远啊 |









说点什么...