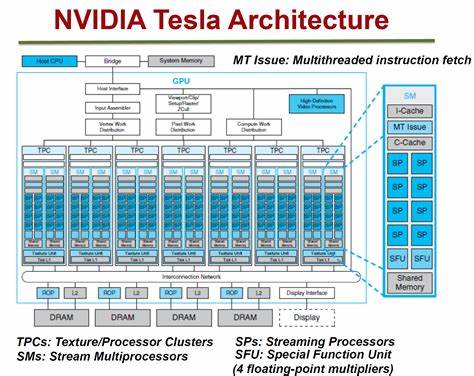
引言 CUDA是一种用于GPU编程的并行计算平台,广泛用于科学计算、深度学习、图形渲染等领域。CUDA的高性能部分依赖于其复杂的硬件结构和智能的线程调度机制。在本文中,我们将深入探讨CUDA硬件结构和调度机制,并提供示例代码,以帮助开发人员更好地理解并利用这些关键概念。 CUDA硬件结构 CUDA设备通常包括多个Streaming Multiprocessors(SMs),每个SM包含多个CUDA核心。这些SMs是并行工作的单元,每个核心能够同时执行一个线程。了解CUDA的硬件结构对于有效利用GPU资源至关重要。 1. Streaming Multiprocessors(SMs):每个SM包含多个CUDA核心。它们是并行执行指令的基本单元。了解SMs的数量和性能对于确定GPU的总性能至关重要。 2. CUDA核心:每个SM包含多个CUDA核心,它们负责执行指令。这些核心可以执行多线程,因此有效的线程调度对于提高性能至关重要。 3. 寄存器文件:CUDA核心拥有自己的寄存器文件,用于存储变量和中间计算结果。了解寄存器文件的大小和分布可以帮助你更好地优化代码。 4. 共享内存:SM中的线程可以访问共享内存,这是一个低延迟的内存区域。了解共享内存的使用和管理对于减少内存访问延迟非常重要。 5. 全局内存:全局内存是GPU中的主要存储区域,通常速度较慢。理解全局内存的使用和性能特征对于避免内存瓶颈至关重要。 线程调度机制 CUDA的线程调度机制是其高性能的关键。线程束、warps和线程块是其中的重要概念。 1. 线程束(Thread Warp):线程束是一组32个线程,它们同时执行相同的指令。了解线程束的概念有助于优化代码,以充分利用并行性。 2. Warps:Warps是SM上的线程束集合。每个SM可以同时执行多个warps。优化代码以充分利用warps的并行性可以提高性能。 3. 线程块(Thread Block):线程块是线程的逻辑组织。线程块内的线程可以协同工作,并使用共享内存。合理定义线程块大小对于性能至关重要。 实际示例 让我们通过一个简单的向量加法示例来说明上述概念的应用: ```cpp __global__ void vectorAdd(float* A, float* B, float* C, int numElements) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < numElements) { C[i] = A[i] + B[i]; } } ``` 在这个示例中,我们利用线程块和线程束来并行执行向量加法。线程块的大小和数量以及线程束的数量都会影响性能,因此需要根据硬件结构和任务的特点进行优化。 结论 深入了解CUDA的硬件结构和线程调度机制对于优化GPU计算至关重要。合理利用SMs、CUDA核心、寄存器文件、共享内存和全局内存,以及理解线程束、warps和线程块的概念,将有助于提高CUDA应用程序的性能。不断学习和实践是优化GPU计算的关键。 参考文献 - "NVIDIA CUDA Toolkit Documentation." NVIDIA Developer. https://developer.nvidia.com/cuda-toolkit (访问日期:2023年10月25日)。 |





说点什么...