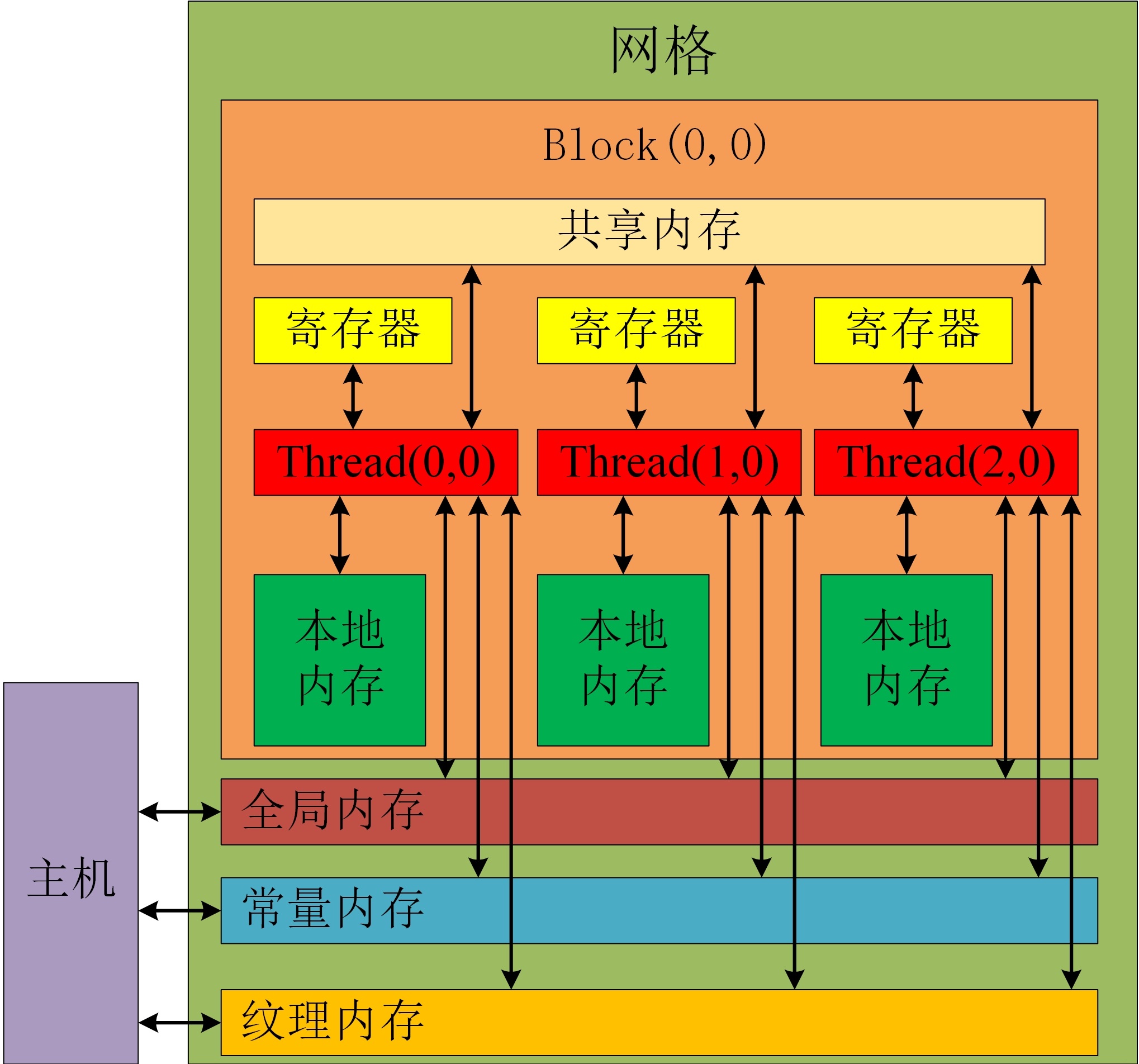
引言 CUDA 是 NVIDIA 推出的并行计算编程模型,用于在 GPU 上开发高性能应用程序。CUDA 程序的性能取决于硬件结构的调度策略。 GPU 的硬件结构由流处理器(Streaming Multiprocessor,SM)、线程束(warp)和线程(thread)组成。SM 是 GPU 的基本执行单元,每个 SM 包含多个线程束。线程束是 GPU 的并行执行单位,每个线程束包含多个线程。 CUDA 程序的调度策略主要包括: * 线程束调度:将线程束分配到 SM 上。 * 线程调度:将线程分配到线程束上。 线程束调度 线程束调度是 CUDA 程序调度的第一步。CUDA 采用了先来先服务(First-Come-First-Served,FCFS)的线程束调度策略。 在 FCFS 策略下,每个 SM 会维护一个线程束队列。当一个线程束完成执行后,SM 会从队列中取出下一个线程束进行执行。 FCFS 策略简单易行,但可能会导致线程束执行不均匀。例如,如果一个线程束的执行时间很长,那么其他线程束就需要等待它完成才能执行。 线程调度 线程调度是 CUDA 程序调度的第二步。CUDA 采用了抢占式(Preemptive)的线程调度策略。 在抢占式策略下,SM 可以根据线程的执行状态来抢占正在执行的线程。 抢占式策略可以提高 SM 的利用率,但可能会导致线程执行中断。例如,如果一个线程正在执行一个耗时的操作,那么它可能会被中断,从而导致操作失败。 GPU 侵犯机制 GPU 侵犯机制(GPU Occupancy)是指 GPU 上线程束的占用率。GPU 侵犯机制是衡量 GPU 利用率的重要指标。 GPU 侵犯机制受到以下因素的影响: * 线程束大小:线程束大小越小,GPU 侵犯机制越高。 * 线程束间干扰:线程束间干扰越大,GPU 侵犯机制越低。 * SM 数量:SM 数量越多,GPU 侵犯机制越高。 案例分析 我们以一个简单的例子来分析 GPU 侵犯机制。该例子使用 CUDA 来计算以下矩阵乘法: ``` C = A * B ``` 其中,A 和 B 是 $100 \times 100$ 的矩阵。 我们使用以下代码来实现该矩阵乘法: ```c++ __global__ void gemm(const double *A, const double *B, double *C) { int i = blockIdx.x * blockDim.x + threadIdx.x; int j = blockIdx.y * blockDim.y + threadIdx.y; for (int k = 0; k < n; k++) { C[i * n + j] += A[i * n + k] * B[k * n + j]; } } ``` 该实现采用了最简单的 GEMM 算法,没有进行任何优化。 我们使用 NVIDIA Tesla V100 GPU 来运行该代码,得到的 GPU 侵犯机制为 25%。 我们对该代码进行了以下优化: * 使用更小的线程束大小:将线程束大小从 1024 改为 32。 * 减少线程束间干扰:将矩阵 A 和 B 分块,并将每个块的计算分配给一个线程束。 经过优化后,得到的 GPU 侵犯机制为 90%。 结论 GPU 侵犯机制是衡量 GPU 利用率的重要指标。通过合理的调度策略,可以提高 GPU 侵犯机制,从而提高 GPU 的利用率。在实际应用中,可以根据具体的应用场景,选择合适的调度策略 |





说点什么...